Binomialverteilte ZV
Wahrscheinlichkeitsrechnung
Zufallsexperiment
Wir betrachten ein (wiederholbares) ZE, das  -mal durchgeführt wird. Bei jeder Durchführung wird beobachtet, ob ein bestimmtes (vorher festgelegtes) Ereignis eintritt oder nicht. Abkürzend sagt man:
-mal durchgeführt wird. Bei jeder Durchführung wird beobachtet, ob ein bestimmtes (vorher festgelegtes) Ereignis eintritt oder nicht. Abkürzend sagt man: 

Wichtig ist dabei, dass die einzelnen Durchführungen
- unabhängig voneinander sind
- unter gleichen Bedingungen stattfinden
Zufallsvariable T
Man fasst den gesamten Vorgang nun als ein ZE auf. Die ZV  , die die Anzahl der Treffer beschreibt, nennt man dann binomialverteilt mit Versuchszahl
, die die Anzahl der Treffer beschreibt, nennt man dann binomialverteilt mit Versuchszahl  und Trefferwahrscheinlichkeit
und Trefferwahrscheinlichkeit ![{\textstyle p\in [0,1]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/bbef154480465a13bd6618e93aa4f1c864030124.svg) und es gilt:
und es gilt: 
Begründung
Dies lässt sich wie folgt begründen:
Für eine bestimmte Abfolge von  Treffern und
Treffern und  Nicht-Treffern ist die Wahrscheinlichkeit (entsprechend einem Pfad in einem Baumdiagramm) das Produkt aus -Faktoren, von denen Faktoren
Nicht-Treffern ist die Wahrscheinlichkeit (entsprechend einem Pfad in einem Baumdiagramm) das Produkt aus -Faktoren, von denen Faktoren  sind und Faktoren
sind und Faktoren  . Sie hat also den Wert
. Sie hat also den Wert  .
.
Es gibt jedoch mehrere Pfade, in denen genau Treffer vorkommen. Da diese Treffer an von Stellen vorkommen können, sind es insgesamt  Möglichkeiten.
Möglichkeiten.
Beispiel 1
Für  und
und  ist
ist

Beispiel 2.1
Für  und
und  ist beispielsweise:
ist beispielsweise:

Wahrscheinlichkeiten



Beispiel 3
Für und ist beispielsweise:

Beispiel 4
Für und ist beispielsweise: 
Beispiel 5
Hier einige weitere Beispiele:
Beispiel 6
Interaktive App zur Binomialverteilung:
Link und Download
In R

Aufgabe 1
Berechnen Sie für eine binomialverteilte ZV mit den jeweils angegebenen Werten für und die angegebenen Wahrscheinlichkeiten:
- Für
 und
und  :
:  für alle
für alle 
- Für
 und
und  :
: 
- Für
 und
und  :
: 
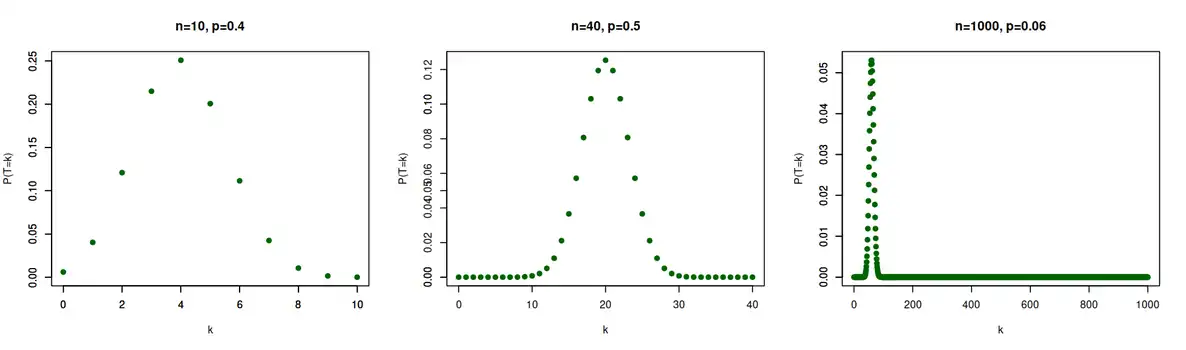
Beispiele für Binomialverteilung 1
- (Ziehen mit Zurücklegen) Aus einer Lostrommel, die
 Kugeln enthält, von denen
Kugeln enthält, von denen  rot sind, werden nacheinander mit Zurücklegen Kugeln gezogen. Die ZV für die Anzahl roten Kugeln unter den Gezogenen ist binomialverteilt mit Versuchszahl und Trefferwahrscheinlichkeit
rot sind, werden nacheinander mit Zurücklegen Kugeln gezogen. Die ZV für die Anzahl roten Kugeln unter den Gezogenen ist binomialverteilt mit Versuchszahl und Trefferwahrscheinlichkeit  .
.
- Wenn man
 -mal würfelt, ist die ZV für die Zahl der gewürfelten
-mal würfelt, ist die ZV für die Zahl der gewürfelten  -en binomialverteilt mit Versuchszahl
-en binomialverteilt mit Versuchszahl  und Trefferwahrscheinlichkeit
und Trefferwahrscheinlichkeit  .
.
Beispiele für Binomialverteilung 2
- Wenn ein Medikament, das mit einer Wahrscheinlichkeit von
 eine bestimmte Nebenwirkung verursacht, von
eine bestimmte Nebenwirkung verursacht, von  Patienten eingenommen wird, ist die ZV für die Zahl der Patienten, bei denen die Nebenwirkung auftritt, binomialverteilt mit Versuchszahl
Patienten eingenommen wird, ist die ZV für die Zahl der Patienten, bei denen die Nebenwirkung auftritt, binomialverteilt mit Versuchszahl  und Trefferwahrscheinlichkeit
und Trefferwahrscheinlichkeit  .
.
Beispiele für Binomialverteilung 3
- Wenn ein Basketballspieler Freiwürfe macht, ist die ZV für die Zahl seiner Treffer nur unter folgenden Annahmen binomialverteilt:
- Es gibt eine Trefferwahrscheinlichkeit , die immer gleich groß ist.
- Treffer bzw. Nicht-Treffer bei bestimmten Würfen beeinflussen nicht die Trefferwahrscheinlichkeit für die anderen Würfe.
Beispiele für Binomialverteilung 4
- Die Wahrscheinlichkeit für eine Mädchengeburt betrage
 . Unter
. Unter  Neugeborenen ist dann die ZV für die Zahl der Mädchen binomialverteilt mit Versuchszahl
Neugeborenen ist dann die ZV für die Zahl der Mädchen binomialverteilt mit Versuchszahl  und Trefferwahrscheinlichkeit
und Trefferwahrscheinlichkeit  .
.
Beispiel Aufgaben 1
- Bei einem Multiple-Choice Test gibt es bei jeder der 20 Fragen 4 Antwortmöglichkeiten, von denen genau eine Antwort richtig ist. Ein unvorbereiteter Teilnehmer kreuzt willkürlich jeweils eine Antwort an. Wie groß ist die Wahrscheinlichkeit, dass er


richtig beantwortet?
- Wie groß ist die Wahrscheinlichkeit beim 10-maligen Werfen von 2 Würfeln
 die Augensumme
die Augensumme  zu erzielen?
zu erzielen?
Beispiel Aufgaben 2
- Auf dem Weg zur Arbeit ist eine Ampel jeden Tag mit der Wahrscheinlichkeit
 rot. Berechnen Sie die Wahrscheinlichkeit, dass die Ampel an genau von 7 Tagen Rot ist
rot. Berechnen Sie die Wahrscheinlichkeit, dass die Ampel an genau von 7 Tagen Rot ist  .
.
- Ein Bäcker knetet in einen Teig für 100 Rosinenbrötchen 200 Rosinen gut unter. Dann wird der Teig in 100 gleiche Teile geschnitten. Mit welcher Wahrscheinlichkeit enthält ein rein zufällig ausgewähltes Brötchen dieser Charge

Rosinen?
Zusatzfrage: Wie viele Rosinen muss der Bäcker in den Teig für 100 Rosinenbrötchen kneten, damit ein auf gut Glück ausgewähltes Brötchen mit einer Mindestwahrscheinlichkeit von  mindestens eine Rosine enthält?
mindestens eine Rosine enthält?
Erwartungswert und Varianz einer binomialverteilten ZV
Für eine binomialverteilte ZV mit Versuchszahl und Trefferwahrsch. gilt: 
EW und Varianz der relativen Häufigkeit
Ist eine binomialverteilte ZV mit Versuchszahl und Trefferwahrscheinlichkeit , so beschreibt die ZV  die relative Häufigkeit des Ereignisses "Treffer" in der Versuchsserie.
die relative Häufigkeit des Ereignisses "Treffer" in der Versuchsserie.
Es gilt: 
Beispiel 1
Für und haben wir oben bereits die Wahrscheinlichkeitsverteilung bestimmt. Daraus ergibt sich:

Tatsächlich ist  und
und  .
.
Beispiel 2.1
Für  und
und  berechnen wir zunächst
berechnen wir zunächst  für alle möglichen Werte
für alle möglichen Werte  :
:

Beispiel 2.2
Daraus ergibt sich:

Tatsächlich ist  und
und  .
.
Aufgabe 1
Sie werfen eine Münze 20 mal. Bestimmen Sie die folgenden Wahrscheinlichkeiten (Kopf ist "Treffer"):





Aufgabe 2
Bei dem Spiel Kniffel würfeln Sie mit fünf Würfeln (normalerweise bis zu dreimal, dies soll der Einfachheit wegen vernachlässigt werden). Wie hoch ist die Wahrscheinlichkeit,
- ein Kniffel (fünf Gleiche) zu würfeln.
- einen Vierer-Pasch (mindestens zwei Vierer) zu werfen.
Bestimmen Sie auch Erwartungswert und Varianz für das Werfen einer bestimmten Zahl.
Schätzungen für p
Problemstellung
Bisher können wir die Wahrscheinlichkeit dafür berechnen, dass die Trefferzahl in einem bestimmten Bereich liegt, wenn wir die Trefferwahrscheinlichkeit kennen. In der Praxis ist man häufig aber mit folgender Situation konfrontiert: 

Unterscheidung
Genauer kann man unterscheiden:
- Die Versuchszahl steht fest und ist bekannt. (In vielen Fällen kann man sogar selbst festlegen.)
- Die Trefferwahrscheinlichkeit liegt fest, ist aber nicht bekannt.
- Die Trefferzahl ist zufällig.
Situation vor und nach der Datenerhebung
Sie wird vor Erhebung der Daten durch die ZV beschrieben. Nach der Datenerhebung liegt dann eine Realisierung  der ZV vor.
der ZV vor.
Schätzungen für können nur auf der konkreten Realisierung (Trefferzahl)  basieren. Da der Schätzung also die zufällige Trefferzahl zugrunde liegt, ist folglich auch die Schätzung vom Zufall abhängig.
basieren. Da der Schätzung also die zufällige Trefferzahl zugrunde liegt, ist folglich auch die Schätzung vom Zufall abhängig.

Punktschätzung für p
Sei eine binomialverteilte ZV mit (bekannter) Versuchszahl und (unbekannter) Trefferwahrscheinlichkeit .
Eine Punktschätzfunktion für ist eine Abbildung:

Punktschätzfunktion vor und nach Datenerhebung
Eine solche Punktschätzfunktion kann aus verschiedenen Blickwinkeln betrachtet werden:
- Vor der Durchführung des ZE ist die Trefferzahl eine ZV. Da die Trefferzahl in die Schätzfunktion eingesetzt werden soll, kann man so auch die Schätzung selbst als ZV
 interpretieren.
interpretieren.
- Nach dem Feststellen einer konkreten Trefferzahl
 kann man diese einfach in die Schätzfunktion einsetzen und erhält so in der Praxis eine konkrete Schätzung
kann man diese einfach in die Schätzfunktion einsetzen und erhält so in der Praxis eine konkrete Schätzung  für .
für .
Beispiel 1.1
(Relative Häufigkeit ist Punktschätzfunktion für ) Die Abbildung:

ist eine Punktschätzfunktion für .
Es stellt sich nun die Frage nach einer sinnvollen Punktschätzfunktion für (es liegt nahe, die relative Häufigkeit  aus Beispiel Beispiel 1.1 zu betrachten) bzw. allgemeiner was überhaupt sinnvolle
aus Beispiel Beispiel 1.1 zu betrachten) bzw. allgemeiner was überhaupt sinnvolle Eigenschaften für eine solche Schätzfunktion sind. Um dies zu beurteilen, sollte man den Standpunkt vor der Datenerhebung einnehmen.
Eigenschaften für eine solche Schätzfunktion sind. Um dies zu beurteilen, sollte man den Standpunkt vor der Datenerhebung einnehmen.
Relative Häufigkeit als Zufallsvariable
Die relative Häufigkeit ist erwartungstreu, effizient und konsistent:
Fasst man die relative Häufigkeit als Zufallsvariable auf, so gilt:
- ist erwartungstreu für , das heißt es gilt:
 für alle
für alle
Dabei ist  der (von abhängige) EW von .
der (von abhängige) EW von .
- Es gilt:
 für alle
für alle
Dabei ist  die (von abhängige) Varianz von .
die (von abhängige) Varianz von .
- ist konsistent, das heißt für alle und alle
 gilt:
gilt: 
Dabei bedeutet  das die Wahrscheinlichkeit in Abhängigkeit von berechnet wurde.
das die Wahrscheinlichkeit in Abhängigkeit von berechnet wurde.
Das Maximum-Likelihood-Prinzip
Neben den schon genannten Qualitätskriterien für Punktschätzfunktionen (Erwartungstreue, Effizienz und Konsistenz) gibt es noch einen anderen Zugang, die sogenannte Maximum-Likelihood-Methode. Dabei wird für den unbekannten Parameter (hier die Trefferwahrscheinlichkeit ) der Wert geschätzt, für den die beobachteten Daten (hier die Trefferzahl ) möglichst wahrscheinlich waren.
Maximum-Likelihood-Schätzung 1
Die Maximum-Likelihood-Schätzung ![{\textstyle S_{ML}:\{0,\ldots ,n\}\to [0,1]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/64e25245b099a4133daae60ba4e6def41529ddc6.svg) ist also wie folgt definiert:
ist also wie folgt definiert:
Für  ist
ist ![{\textstyle S_{ML}(k)\in [0,1]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/7052f4f159b12b4410d94f92bdb76239d07f1e00.svg) die (globale) Maximumstelle der Funktion
die (globale) Maximumstelle der Funktion ![{\displaystyle L:[0,1]\to [0,1],\ L(p)=\underbrace {{n \choose k}p^{k}(1-p)^{n-k}} _{=P(T=k)\ {\text{(abhängig von p)}}}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/3767ff43229b6b164f1e69b223eb02f3e4e2b0ca.svg)
( steht für Likelihood-Funktion)
steht für Likelihood-Funktion)
Maximum-Likelihood-Schätzung 2
Die Wahrscheinlichkeit wird bei Treffern in Versuchen also als der Wert geschätzt, für den die Wahrscheinlichkeit  für genau Treffer maximal ist.
für genau Treffer maximal ist.
Man kann zeigen, (vergleiche die folgenden Beispiele) dass stets  gilt. Auch mit dieser Methode erhält man also die relative Häufigkeit als sinnvolle Schätzung für .
gilt. Auch mit dieser Methode erhält man also die relative Häufigkeit als sinnvolle Schätzung für .
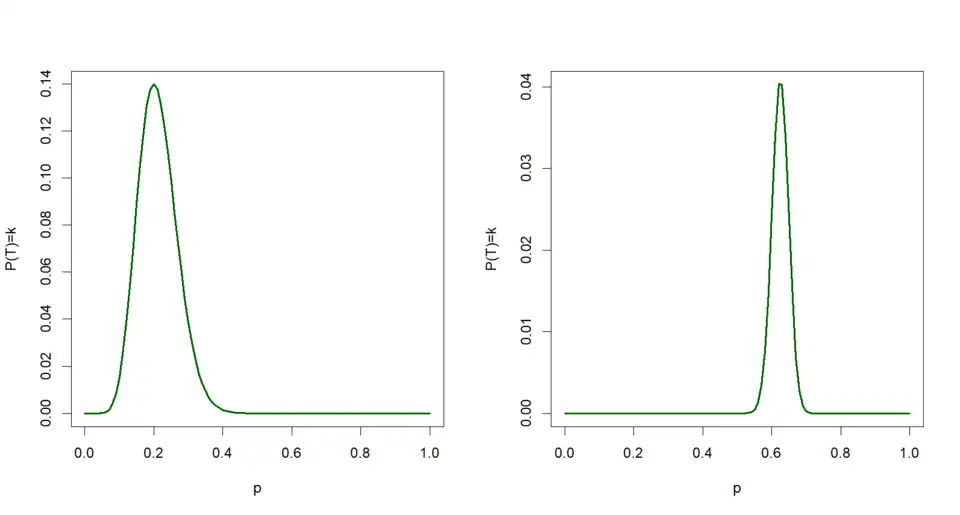
Beispiel 2
n = 50, k =10 bzw. n=400, k = 250
Intervallschätzungen für p
Ein (für die Praxis relevantes) Problem bei den bisher behandelten Punktschätzungen für ist, dass es sich bei den Gütekriterien (Erwartungstreue, Effizienz und Konsistenz) für die Schätzfunktionen lediglich um qualitative Aussagen handelt.
Ziel ist es nun, Schätzungen für zu formulieren, die man auch quantitativ beurteilen kann. Eine solche hat die Form: ![{\displaystyle {\text{Der unbekannte Wert}}\ p\ {\text{liegt in einem Intervall der Form}}\ [p_{U},p_{O}].}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/9395495e513cd6c852f14334425b09857d7d0463.svg)
Situation
Wir betrachten die folgende Situation:
Zu einer binomialverteilten ZV ist die Versuchszahl fest und bekannt und die Trefferwahrscheinlichkeit fest, aber unbekannt. Basierend auf der vom Zufall abhängigen Trefferzahl soll nun eine Intervallschätzung
![{\displaystyle p\in [p_{U},p_{O}]=[p_{U}(k),p_{O}(k)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/c77c31e6f9222db517577f2fea800a75c96aa8a4.svg)
für vorgenommen werden.
Betrachtung vor der Datenerhebung
Erneut nehmen wir die folgenden beiden Standpunkte ein:
Vor der Durchführung des ZE ist die Trefferzahl eine ZV. Da die Trefferzahl in die Intervallschätzfunktion eingesetzt werden soll, hängt somit auch das berechnete Intervall
![{\textstyle B(T)=[p_{U}(T),p_{O}(T)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/fe7ecd621280aa6d934fb2550fc4c7036d62d8d5.svg)
vom Zufall ab. Damit ist es auch vom Zufall abhängig, ob die resultierende Aussage
![{\textstyle p\in [p_{U}(T),p_{O}(T)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/086798063649b7521a20fe70352c2d1365dd1f63.svg)
wahr oder falsch sein wird.
Betrachtung nach der Datenerhebung
Nach dem Feststellen einer konkreten Trefferzahl kann man diese einfach in die Schätzfunktion einsetzen und erhält so in der Praxis eine konkrete Intervallschätzung
![{\textstyle B(k)=[p_{U}(k),p_{O}(k)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/6e5ec87d00e9ec61130eb9f859bba9276ecad39e.svg)
für . Die Aussage
![{\textstyle p\in [p_{U}(k),p_{O}(k)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/82cb4ebe70b582534d2d4291b744f2a9848c0b99.svg)
ist dann nicht mehr vom Zufall abhängig, sondern entweder wahr oder falsch. (Leider weiß man nicht, welcher der beiden Fälle eingetreten ist, da man nicht kennt.)
Intervallschätzung als Abbildung
Sei ![{\textstyle {\mathcal {I}}_{[0,1]}=\left\{[a,b];\ 0\leq a\leq b\leq 1\right\}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/4ce6809615a9e011c72abcf663ecc1d9cf61c687.svg) die Menge der abgeschlossenen Teilintervalle von
die Menge der abgeschlossenen Teilintervalle von ![{\textstyle [0,1]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/aae4e869850c7966cf425a2022a45dd3eeb8b86a.svg) .
.
Eine Intervallschätzung (bzw. Bereichsschätzung) für ist eine Abbildung: ![{\displaystyle {\begin{array}{rccc}B:&\underbrace {\{0,\ldots ,n\}} _{\text{Menge der möglichen Werte für die ZV T}}&\to &\underbrace {{\mathcal {I}}_{[0,1]}} _{\begin{array}{c}{\text{Menge von Teilmengen der Menge}}\\{\text{aller in Frage kommenden Werte von p}}\end{array}}\\&\underbrace {k} _{\text{konkrete Trefferzahl}}&\mapsto &\underbrace {B(k)=[p_{U}(k),p_{O}(k)]} _{{\text{konkrete Intervallschätzung für }}p}\end{array}}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/edbadbdbc36a83f1d3494d65d95fb7eb9e537ec3.svg)
Beurteilung einer Intervallschätzung
Um Intervallschätzungen sinnvoll beurteilen zu können, untersuchen wir die (vom unbekannten Parameter abhängige) Wahrscheinlichkeit dafür, dass man ein "korrektes Intervall" (also eines, dass tatsächlich enthält) berechnet, wenn man die (vom Zufall abhängige) Trefferzahl einsetzt.
Überdeckungswahrscheinlichkeit und Konfidenzniveau
Gegeben sei eine Intervallschätzfunktion: ![{\displaystyle B:\{0,\ldots ,n\}\to {\mathcal {I}}_{[0,1]},\ B(k)=[p_{U}(k),p_{O}(k)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/c8925badd3b40c2a2e9ec62957e11da17f75fc82.svg)
Überdeckungswahrscheinlichkeit
Für einen denkbaren Parameterwert definiert man die Überdeckungswahr-scheinlichkeit von  an der Stelle durch:
an der Stelle durch:
![{\displaystyle P_{B}(p)=P(B(T)\ni p)=P\left([p_{U}(T),p_{O}(T)]\ni p\right)=\sum \limits _{k\in \{0,\ldots ,n\},B(k)\ni p}{n \choose k}\cdot p^{k}\cdot (1-p)^{n-k}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/28909fe2a0c846d750e04f6fb1d0221655fdc650.svg)
Anmerkung
Die Schreibweise  ist mathematisch gleichbedeutend zu
ist mathematisch gleichbedeutend zu  , hat aber den Vorteil, dass dabei deutlich wird, dass
, hat aber den Vorteil, dass dabei deutlich wird, dass  (und nicht ) vom Zufall abhängt. Anstatt zu sagen: ist in enthalten." formuliert man daher auch fängt ein."
(und nicht ) vom Zufall abhängt. Anstatt zu sagen: ist in enthalten." formuliert man daher auch fängt ein."
Konfidenzniveau
Gilt  für eine feste Zahl
für eine feste Zahl ![{\textstyle \delta \in [0,1]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/7e75c124d43ecb4ceaf939b5f673971d4f1aefc4.svg) , so sagt man auch:
, so sagt man auch:
"Die Intervallschätzung hält das Konfidenzniveau  ein."
ein."
Bedeutung 1
Die Überdeckungswahrscheinlichkeit entspricht der Wahrscheinlichkeit dafür, dass man ein korrektes Intervall erhalten wird, wenn man die zufällige Trefferzahl in die Intervallschätzung einsetzt. Da die Überdeckungswahrscheinlichkeit vom unbekannten Parameter abhängt, kann man sie in der Praxis nicht berechnen.
Bedeutung 2
Weiß man aber (aufgrund theoretischer Überlegungen), dass eine Intervallschätzung ein bestimmtes Konfidenzniveau einhält, so ist (unabhängig vom wahren Wert von ) garantiert, dass man MINDESTENS mit der Wahrscheinlichkeit ein korrektes Intervall erhalten wird, wenn man die zufällige Trefferzahl in die Intervallschätzung einsetzt.
In der Praxis sollte man nur Intervallschätzungen verwenden, von denen man weiß, dass sie ein hohes Konfidenzniveau (üblich sind  oder
oder  oder
oder  ) einhalten.
) einhalten.
Ziel
Wie findet man zu einem vorgegebenen Konfidenzniveau  eine Intervallschätzung, die dieses Konfidenzniveau garantiert einhält.
eine Intervallschätzung, die dieses Konfidenzniveau garantiert einhält.
Intervallschätzung nach Clopper-Pearson
Vorgegeben sei ![{\textstyle \delta \in ]0,1[}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/a0e6172b1124969f7a4158fa7792a3bfb3944a7b.svg) .
.
Für bestimmt man  und
und  aus den Gleichungen:
aus den Gleichungen:


Dann hält die Intervallschätzung ![{\textstyle B:\{0,\ldots ,n\}\to {\mathcal {I}}_{[0,1]},\ B(k)=[p_{U}(k),p_{O}(k)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/6a990730dade7c9f0d6f701ecd63f8999e889ec8.svg) garantiert das Konfidenzniveau ein.
garantiert das Konfidenzniveau ein.
Ausnahmen
Ausnahme sind folgende Sonderfälle:
Für  setze
setze  , für
, für  setze
setze  .
.
Anmerkung
Obige Bestimmungsgleichungen für  und
und  sind ohne Computereinsatz kaum zu lösen. Konfidenzintervalle nach Clopper-Pearson können aber in R direkt berechnet werden. Der Befehl
sind ohne Computereinsatz kaum zu lösen. Konfidenzintervalle nach Clopper-Pearson können aber in R direkt berechnet werden. Der Befehl
![{\displaystyle \quad \color {blue}{{\text{binom.test(}}k,n,{\text{conf.level}}=\delta )\${\text{conf.int}}[1:2]}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/cb46869071bd85e7b946034cf57351afbaf166d7.svg)
ergibt das Konfidenzintervall zum Vertrauensniveau bei Treffern in Versuchen.
Bemerkung 1
Obergrenzen für die Wahrsch. für Über- bzw. Unterschätzung von :
Die Grenzen und der Intervallschätzung nach Clopper-Pearson aus Satz Intervallschätzung nach Clopper-Pearson sind so gewählt, dass die Wahrscheinlichkeiten für "Unterschätzung" und "Überschätzung" von durch dieselbe Grenze beschränkt sind. Genauer: 
Bemerkung 2
Zusammen ergibt sich damit
![{\displaystyle P{\big (}\underbrace {p\notin [p_{U}(T),p_{O}(T)]} _{\text{falsche Schätzung}}{\big )}\leq 1-\delta }](../_assets_/eb734a37dd21ce173a46342d1cc64c92/efc6ecfbe5fb9aa852ac076b67a61c9a4cf27763.svg)
und folglich
![{\displaystyle \quad P{\big (}\underbrace {p\in [p_{U}(T),p_{O}(T)]} _{\text{korrekte Schätzung}}{\big )}\geq \delta }](../_assets_/eb734a37dd21ce173a46342d1cc64c92/c6eed6dfa03010f8ec20eb01a746b383cdbefc3b.svg)
Dass man diesen Aussagen überhaupt eine Wahrscheinlichkeit zuschreiben kann, liegt daran dass die Intervallgrenzen  und
und  zufällig sind (und nicht etwa der unbekannte, aber feste Wert ).
zufällig sind (und nicht etwa der unbekannte, aber feste Wert ).
Beispiel 1.1
Für  und
und  ergeben sich die Intervallgrenzen als Lösungen der Gleichung
ergeben sich die Intervallgrenzen als Lösungen der Gleichung

und

Beispiel 1.2
Hierbei wären also Polynome vom Grad aufzulösen. Mit R berechnen wir:
![{\displaystyle {\begin{array}{l}{\text{Für }}\delta =0.6{\text{ ist }}[p_{U},p_{O}]=[0.665,0.751].\\{\text{Für }}\delta =0.8{\text{ ist }}[p_{U},p_{O}]=[0.644,0.769].\\{\text{Für }}\delta =0.9{\text{ ist }}[p_{U},p_{O}]=[0.626,0.784].\\{\text{Für }}\delta =0.99{\text{ ist }}[p_{U},p_{O}]=[0.580,0.819].\end{array}}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/bd53e39653db4b710bf37d7df934e586efa82428.svg)
Beispiel 2.1
Für erhält man zum Konfidenzniveau  mit der Clopper-Pearson-Methode abhängig von die folgenden (mit R berechneten) Konfidenzintervalle :
mit der Clopper-Pearson-Methode abhängig von die folgenden (mit R berechneten) Konfidenzintervalle :
![{\displaystyle {\begin{array}{|c||c|c|c|c|c|c|c|}\hline k&0&1&2&3&4&5&6\\\hline B(k)&[0,0.109]&[0.005,0.181]&[0.027,0.245]&[0.056,0.304]&[0.090,0.361]&[0.127,0.415]&[0.166,0.467]\\\hline \hline k&7&8&9&10&11&12&13\\\hline B(k)&[0.207,0.518]&[0.249,0.567]&[0.292,0.615]&[0.338,0.662]&[0.385,0.707]&[0.433,0.751]&[0.482,0.793]\\\hline \hline k&14&15&16&17&18&19&20\\\hline B(k)&[0.533,0.834]&[0.585,0.873]&[0.639,0.910]&[0.696,0.944]&[0.755,0.973]&[0.819,0.995]&[0.891,1]\\\hline \end{array}}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/ae28562caa4f93479a329f50841cb340e86a3852.svg)
Beispiel 2.2
Wir berechnen für verschiedene denkbare Werte von , die Überdeckungswahrscheinlichkeit (also die Wahrscheinlichkeit dafür, dass die Intervallschätzung korrekt ist):
Beispiel 2.3
Angenommen, es ist . Dann ist die Intervallschätzung für  korrekt. Die Wahrscheinlichkeit dafür ist:
korrekt. Die Wahrscheinlichkeit dafür ist:

Beispiel 2.4
Angenommen, es ist  . Dann ist die Intervallschätzung für
. Dann ist die Intervallschätzung für  korrekt. Die Wahrscheinlichkeit dafür ist:
korrekt. Die Wahrscheinlichkeit dafür ist:

Beispiel 2.5
Angenommen, es ist  . Dann ist die Intervallschätzung für
. Dann ist die Intervallschätzung für  korrekt. Die Wahrscheinlichkeit dafür ist:
korrekt. Die Wahrscheinlichkeit dafür ist: 
Beispiel 2.6
Angenommen, es ist  . Dann ist die Intervallschätzung für
. Dann ist die Intervallschätzung für  korrekt. Die Wahrscheinlichkeit dafür ist:
korrekt. Die Wahrscheinlichkeit dafür ist:

Korrektheit der Schätzung
Es ist bewiesen, dass die Schätzung bei beliebigem immer mindestens mit der Wahrscheinlichkeit korrekt ist.
Größe der Konfidenzintervalle 1
Bei fester relativer Häufigkeit werden die Konfidenzintervalle mit wachsender Versuchszahl kleiner (mit mehr Versuchen erreicht man eine höhere Genauigkeit) und mit wachsendem Konfidenzniveau größer (ein höheres Konfidenzniveau "bezahlt"man mit einer ungenaueren Aussage). Man beachte die Größenordnungen dieser Veränderungen anhand der folgenden (mit R berechneten) Konfidenzintervalle:
Größe der Konfidenzintervalle 2
![{\displaystyle {\begin{array}{|cc|c|c|c|c|c|}\hline &k/n&3/10&30/100&300/1000&3000/10000&30000/100000\\\delta &&&&&&\\\hline &&&&&&\\0.6&&\quad [0.157,0.484]\quad &\quad [0.258,0.346]\quad &\quad [0.287,0.313]\quad &\quad [0.296,0.304]\quad &\quad [0.298,0.302]\quad \\&&&&&&\\\hline &&&&&&\\0.8&&[0.115,0.552]&[0.239,0.367]&[0.281,0.320]&[0.294,0.306]&[0.298,0.302]\\&&&&&&\\\hline &&&&&&\\0.9&&[0.087,0.607]&[0.224,0.385]&[0.276,0.325]&[0.292,0.308]&[0.297,0.303]\\&&&&&&\\\hline &&&&&&\\0.95&&[0.066,0.653]&[0.212,0.400]&[0.271,0.330]&[0.291,0.310]&[0.297,0.303]\\&&&&&&\\\hline &&&&&&\\0.99&&[0.037,0.735]&[0.189,0.431]&[0.263,0.339]&[0.288,0.312]&[0.296,0.304]\\&&&&&&\\\hline \end{array}}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/eb918ca775d5efc864025a0a3443c9b0beddbd8f.svg)
Bemerkung Verwendung von Intervallschätzungen in der Praxis 1
In der Praxis ist bei der Verwendung von Intervallschätzungen wie folgt vorzugehen:
1. Zunächst macht man sich die Situation klar: Die Trefferwahrscheinlichkeit einer Binomialverteilung ist unbekannt (aber fest, d.h. nicht vom Zufall abhängig).
2. Man legt fest:
- das Verfahren, mit dem man die Intervallschätzung berechnen wird. (z.B. zweiseitiger Test nach Clopper-Pearson).
Bemerkung Verwendung von Intervallschätzungen in der Praxis 2
- eine Versuchszahl
zu beachten:
Hohe Werte von führen zu einem engeren Konfidenzintervall.
- ein Konfidenzniveau
zu beachten:
Hohe Werte von entsprechen einer höheren Untergrenze für die Wahrscheinlichkeit einer korrekten Schätzung, führen aber zu einem breiteren Konfidenzintervall. Sinnvoll ist z.B. .
Bemerkung Verwendung von Intervallschätzungen in der Praxis 3
3. Man führt die Versuchsreihe durch und stellt die Trefferzahl fest.
Zu beachten:
Wichtig bei einer Binomialverteilung ist, dass die einzelnen Versuche unabhängig voneinander und immer unter den gleichen Bedingungen durchgeführt werden.
Bemerkung Verwendung von Intervallschätzungen in der Praxis 4
4. Man berechnet das Konfidenzintervall ![{\textstyle [p_{U}(k),p_{O}(k)]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/a04ce7ae7767d43f07a4fd33c21be3412f2b2f00.svg) mit der zuvor festgelegten Methode. (Dies kann der Computer erledigen.)
mit der zuvor festgelegten Methode. (Dies kann der Computer erledigen.)
5. Man verkündet das Ergebnis:
![{\textstyle p\in [p_{U}(k),p_{O}(k)]\quad {\text{mit dem Zusatz: }}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/3416b87e258ecbdcc87c6e8b616c34802d2d149e.svg) " Das Konfidenzniveau wurde eingehalten." Damit ist klar: Vor Erhebung der Daten war die Wahrscheinlichkeit ein korrektes Intervall zu erhalten, mindestens . Nach Berechnung des Intervalls kann man damit der Aussage ein gewisses Vertrauen entgegenbringen (aber keine Wahrscheinlichkeit zuweisen, sie ist entweder wahr oder falsch).
" Das Konfidenzniveau wurde eingehalten." Damit ist klar: Vor Erhebung der Daten war die Wahrscheinlichkeit ein korrektes Intervall zu erhalten, mindestens . Nach Berechnung des Intervalls kann man damit der Aussage ein gewisses Vertrauen entgegenbringen (aber keine Wahrscheinlichkeit zuweisen, sie ist entweder wahr oder falsch).
Bemerkung Einseitig begrenzte Konfidenzintervalle
In gewissen Situationen kann es Sinn machen, die Clopper-Pearson-Methode so zu modifizieren, dass man einseitig (statt wie bisher zweiseitig) begrenzte Konfidenzintervalle berechnet.
Beispiel 3
Ist beispielsweise die Wahrscheinlichkeit dafür, dass eine bestimmte Maßnahme einen gewünschten Erfolg erzielt, so könnte es wichtig sein, (möglichst strikt) nach unten abzuschätzen, aber eine Abschätzung von nach oben ist nicht notwendig.
Dazu kann man linkssseitig begrenzte Konfidenzintervalle verwenden.
Beispiel 4
Ist beispielsweise die Wahrscheinlichkeit dafür, dass bei der Einnahme eines Medikaments eine (unerwünschte) Nebenwirkung auftritt, so könnte es wichtig sein, (möglichst strikt) nach oben abzuschätzen, aber eine Abschätzung von nach unten ist nicht notwendig.
Dazu kann man rechtsseitig begrenzte Konfidenzintervalle verwenden.
Einseitig begrenze Konfidenzintervalle
Einseitig begrenze Konfidenzintervalle zu einem vorgegebenen Konfidenzniveau  werden wie folgt berechnet:
werden wie folgt berechnet:
Linksseitig begrenzte Konfidenzintervalle
Bei Treffern aus Versuchen bestimmt man das linksseitig begrenzte Konfidenzintervall ![{\textstyle [p_{U},1]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/5e846dead0e8fe6405f8f10fef5be3ef3c3f0430.svg) zum Vertrauensniveau durch
zum Vertrauensniveau durch

(Sonderfall: Für setze  .)
.)
Rechtsseitig begrenzte Konfidenzintervalle
Bei Treffern aus Versuchen bestimmt man das rechtsseitig begrenzte Konfidenzintervall ![{\textstyle [0,p_{O}]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/c8257acd9794ae1ad0c94eee1cdf27cf6b67f74f.svg) zum Vertrauensniveau durch
zum Vertrauensniveau durch

(Sonderfall: Für setze  .)
.)
Überschätzung bei linksseitig begrenzten Konfidenzintervallen
Linksseitig begrenzte Konfidenzintervalle dürfen den Wert von mit einer Wahrscheinlichkeit von bis zu  überschätzen (statt
überschätzen (statt  wie bei den zweiseitigen Intervallschätzungen). Um dies auszugleichen, unterschätzen sie den Wert von nie (die obere Grenze ist
wie bei den zweiseitigen Intervallschätzungen). Um dies auszugleichen, unterschätzen sie den Wert von nie (die obere Grenze ist  ). Die untere Grenze kann daher im Vergleich zum zweiseitigen Test etwas besser (größer) gewählt werden.
). Die untere Grenze kann daher im Vergleich zum zweiseitigen Test etwas besser (größer) gewählt werden.
Unterschätzung bei rechtsseitig begrenzten Konfidenzintervallen
Rechtsseitig begrenzte Konfidenzintervalle dürfen den Wert von mit einer Wahrscheinlichkeit von bis zu unterschätzen (statt wie bei den zweiseitigen Intervallschätzungen). Um dies auszugleichen, überschätzen sie den Wert von nie (die untere Grenze ist  ). Die obere Grenze kann daher im Vergleich zum zweiseitigen Test etwas besser (kleiner) gewählt werden.
). Die obere Grenze kann daher im Vergleich zum zweiseitigen Test etwas besser (kleiner) gewählt werden.
Berechnung in R
In R berechnet man einseitige Konfidenzintervalle nach Clopper-Pearson mit


 "
" "
"



![{\textstyle \color {grey}{]}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/fe98f0527eff30a9284f431bc8c554743a8f3b62.svg)

" "
" 
Beispiel 5
Konfidenzintervalle im Vergleich für  :
:
![{\displaystyle {\begin{array}{|r||c|c|c|}\hline \delta &0.8&0.9&0.95\\\hline {\text{beidseitig begrenzt}}&[0.512,0.607]&[0.499,0.620]&[0.488,0.630]\\\hline {\text{linksseitig begrenzt}}&[0.527,1]&[0.512,1]&[0.499,1]\\\hline {\text{rechtsseitig begrenzt}}&[0,0.591]&[0,0.607]&[0,0.620]\\\hline \end{array}}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/8c4e1595c6bf3c389833b297590cc1d48e934321.svg)
Bestimmung der Intervallgrenzen
Allgemein bestimmt man aus den Gleichungen 
 die Grenzen einer Intervallschätzung
die Grenzen einer Intervallschätzung ![{\textstyle [p_{U},p_{O}]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/54e3a607043471241696973b644f494187823d4c.svg) , die den Wert von mit einer Wahrscheinlichkeit von höchstens
, die den Wert von mit einer Wahrscheinlichkeit von höchstens  überschätzt und mit einer Wahrscheinlichkeit von höchstens
überschätzt und mit einer Wahrscheinlichkeit von höchstens  unterschätzt.
unterschätzt.
Konfidenzniveau der Schätzung
Das heißt, es gilt

und damit
![{\displaystyle P(p\in [p_{U},p_{O}])\geq 1-\alpha _{U}-\alpha _{O}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/563800937aadf83c96daf4b9794ad0a679f63d11.svg)
Damit ist  das Konfidenzniveau der Schätzung.
das Konfidenzniveau der Schätzung.
Beispiel 6
Für hat man zum Beispiel folgende Möglichkeiten:
![{\displaystyle {\begin{array}{|c|c|c|c|c|c|}\hline &&P(p<p_{U})&P(p>p_{O})&P(p\notin [p_{U},p_{O}])&P(p\in [p_{U},p_{O}])\\\hline \alpha _{U}=0.025\;,\;\alpha _{O}=0.025&zweiseitig,\ \alpha _{U}=\alpha _{O}&\leq 0.025&\leq 0.025&\leq 0.05&\geq 0.95\\\hline \alpha _{U}=0.05\;,\;\alpha _{O}=0&linksseitig\ begrenzt&\leq 0.05&0&\leq 0.05&\geq 0.95\\\hline \alpha _{U}=0\;,\;\alpha _{O}=0.05&rechtsseitig\ begrenzt&0&\leq 0.05&\leq 0.05&\geq 0.95\\\hline \alpha _{U}=0.04\;,\;\alpha _{O}=0.01&zweiseitig,\alpha _{U}\not =\alpha _{O}&\leq 0.04&\leq 0.01&\leq 0.05&\geq 0.95\\\hline \alpha _{U}=0.02\;,\;\alpha _{O}=0.03&zweiseitig,\alpha _{U}\not =\alpha _{O}&\leq 0.02&\leq 0.03&\leq 0.05&\geq 0.95\\\hline \end{array}}}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/c93c357750b50ea334fbb44c5683011d4e8ad078.svg)
Aufgabe 3.1
Bei einer bestimmten Tierart kann bei bestimmten Nachkommen eine morphologische Veränderung beobachtet werden. Die genaue Wahrscheinlichkeit dafür, dass ein neugeborenes Tier die morphologische Veränderung aufweisst, ist aber unbekannt und soll geschätzt werden.
In einer Studie werden dazu  neugeborene Tiere untersucht. Von diesen Tieren weissen
neugeborene Tiere untersucht. Von diesen Tieren weissen  die morphologische Veränderung auf.
die morphologische Veränderung auf.
Aufgabe 3.2
1. Geben Sie anhand der Daten eine Punktschätzung für ab.
2. Stellen Sie die Maximum-Likelihood-Funktion auf
3. Es soll eine Intervallschätzung ![{\textstyle \left[p_{U},p_{O}\right]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/3b6224d308532f27c20e0088bb514933fc73bff9.svg) für zum Konfidenzniveau abgegeben werden.
für zum Konfidenzniveau abgegeben werden.
- Geben Sie die Gleichungen an, anhand derer sich und bestimmen lassen (zweiseitige Intervallschätzung nach Clopper-Pearson). Verwenden Sie dazu wieder die erhobenen Daten ( Nachkommen mit morphologischer Veränderung bei untersuchten). Setzen Sie alle bekannten Zahlenwerte in die Gleichungen ein.
Aufgabe 3.3
- Berechnen Sie mit R die Grenzen und .
- Erklären Sie, inwiefern die Korrektheit der Intervallschätzung
![{\textstyle p\in \left[p_{U},p_{O}\right]}](../_assets_/eb734a37dd21ce173a46342d1cc64c92/48076fc0a9f4d3c97ab34afb235e7a58168b19a6.svg) vom Zufall abhängt. Was weiß man über die Wahrscheinlichkeit, dass die Intervallschätzung korrekt ist? Unterscheiden Sie bei Ihren Erläuterungen die Situation vor und nach der Datenerhebung (bzw. der Berechnung der Intervallgrenzen).
vom Zufall abhängt. Was weiß man über die Wahrscheinlichkeit, dass die Intervallschätzung korrekt ist? Unterscheiden Sie bei Ihren Erläuterungen die Situation vor und nach der Datenerhebung (bzw. der Berechnung der Intervallgrenzen).
Aufgabe 3.4
- Wie ändert sich die Breite des Konfidenzintervalls, wenn man das Konfidenzniveau von
 auf erhöht?
auf erhöht?
- Wie verändert sich die Breite des Konfidenzintervalls, wenn man statt morphologisch auffälligen von untersuchten neugeborenen Tieren eine Untersuchung mit
 von
von  untersuchten neugeborenen Tieren zugrunde legt?
untersuchten neugeborenen Tieren zugrunde legt?
Diese Lernresource können Sie als Wiki2Reveal-Foliensatz darstellen.
Wiki2Reveal
Dieser Wiki2Reveal Foliensatz wurde für den Lerneinheit Kurs:Statistik für Anwender' erstellt der Link für die Wiki2Reveal-Folien wurde mit dem Wiki2Reveal-Linkgenerator erstellt.