Maschinelles Lernen
Einführung
Maschinelles Lernen (ML) ist ein Oberbegriff für die „künstliche“ Generierung von Wissen aus Erfahrung: Ein künstliches System lernt aus Beispielen und kann diese nach Beendigung der Lernphase verallgemeinern.
Lerneinheiten
Lerneinheiten gliedern sich die Betrachtung von
- Klassen maschinellen Lernens
- Lernalgorithmen und Lernregeln
Klassen maschinellen Lernens
Trainingsdaten / Testdaten
Beim maschinellen Lernen unterscheidet man
- Trainingsdaten und
- Testdaten (Validierungsdatensätze).
Lernalgorithmen und Lernregeln

Zeitliche Veränderung eines Systems
In dem Begriff "Maschinelles Lernen" eines System steckt bereits eine zeitliche Veränderung des Systems in der Zeit. In der folgenden Lernressource wird daher ein Maschinelles Lernsystem (kurz ML-System) mit einem Zeitindex versehen, das den Zustand des ML-Systems zum Zeitpunkt .



Maschinelles Lernen als Funktionenfolge
In dieser Lernressource wird Maschinelles Lernen (ML) als eine Funktionenfolge betrachtet, das sich in der Zeit verändert. ist zu jedem Zeitpunkt eine Abbildung von einem Definitionsbereich in den Wertebereich .





Verallgemeinerungsfähigkeit
Ein künstliches System, das aus Beispielen lernt, kann "verallgemeinern", wenn nicht nur für die Trainingsdaten (z.B. Ein-Ausgabepaare aus dem Ein-Ausgabegrundraum) korrekt Ausgaben produziert werden, sondern auch für neue unbekannte Eingaben korrekte bzw. akzeptabel gute Ausgaben produziert werden.

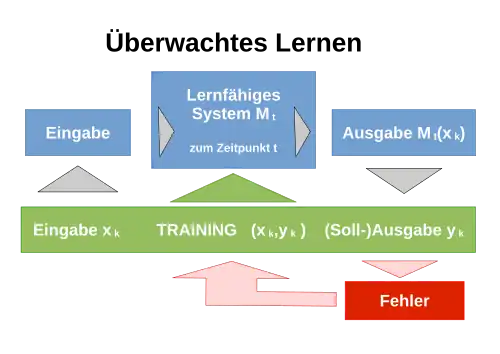
Überwachtes Lernen
Wenn man Ein-Ausgabepaare als Trainingsdaten verwendet, spricht man von überwachtem Lernen. Die entspricht den erwarteten/empfohlenen Ausgaben einer "lehrenden" bzw. trainierenden Instanz. In der Trainingsphase bekommt das System Daten der Form der Ein-Ausgabepaare und in der Testphase.


Unüberwachtes Lernen
Wenn man lediglich Eingaben eine System als Trainingsdaten verwendet, spricht man von unüberwachtem Lernen. Die entspricht den erwarteten/empfohlenen Ausgaben einer "lehrenden" bzw. trainierenden Instanz.

Bestärkendes Lernen
Das bestärkende Lernen ist ein Bereich des maschinellen Lernens, der sich mit der Frage beschäftigt, wie Agenten in einer Umgebung agieren sollten, um einen bestimmten Wert der kumulierten Belohnung zu maximieren.[1][2] Aufgrund seiner Allgemeingültigkeit wird dieses Gebiet auch in vielen anderen Disziplinen untersucht, z. B. in der Spieltheorie, der Kontrolltheorie, dem Operations Research, der Informationstheorie, der simulationsbasierten Optimierung, den Multiagentensystemen, der Schwarmintelligenz, der Statistik und den genetischen Algorithmen. Beim maschinellen Lernen wird die Umgebung normalerweise als Markov-Entscheidungsprozess (MDP) dargestellt. Viele Algorithmen des Verstärkungslernens verwenden Techniken der dynamischen Programmierung.[3] Verstärkungslernalgorithmen setzen keine Kenntnis eines exakten mathematischen Modells des MDP voraus und werden eingesetzt, wenn exakte Modelle nicht durchführbar sind. Verstärkungslernalgorithmen werden in autonomen Fahrzeugen oder beim Lernen eines Spiels gegen einen menschlichen Gegner eingesetzt.
Fehler und deren Optimierung durch Lernen
Zunächst einmal ist die Quantifzierung von Fehlern ein wesentliches Merkmal numerischer Ansätze für die Optimierung von Systemen. Dazu benötigt man grundlegende Definitionen einer Abweichung von Trainingsdaten.
Fehlermaße
Normen, Metriken, Topologie
In der Mathematik liefern Normen, Metriken oder Gaugefunktionale in der Topologie Messinstrumenten, um auf gegeben Räumen Fehler oder Abweichungen zu messen.
Definition - Metrischer Ausgabefehler für Maschinelles Lernen
Sei ein maschineller Lernprozess und ein metrischer Raum. Ein Augabefehler zum Zeitpunkt für die Eingabe für ein zugehöriges Trainingsdatum ist als metrischer Abstand definiert.





Bemerkung - Metrischer Ausgabefehler für Maschinelles Lernen
Mit dem Abstand zwischen der zum Zeitpunkt generierten Ausgabe zu wird die Distanz zum Sollwert gemessen. Das lernenden System verändert seine Ausgabeverhalten mit der Zeit. Der Ausgabefehler für wird zwischen kleiner, wenn gilt:





Dies bedeutet, dass der Abstand zum Sollwert zu einem späteren Zeitpunkt sich verbessert hat.


Optimierung des metrischen Ausgabefehler für Maschinelles Lernen
Die metrische Optimierung des Ausgabefehlers erfolgt aber nicht für einen singulären Eingabewert bzw. für ein Ein-Ausgabepaar , sondern in der Regel für eine endliche Testmenge mit . Die Ein-Ausgabepaare verwendet man dabei nicht für das Training des Maschinellen Lernsystems , sondern für der Test der Güte der Ausgabe von bei unbekannten Ein-Ausgabepaaren aus .





Definition - Metrischer Fehlervektor für Maschinelles Lernen
Sei ein maschineller Lernprozess und ein metrischer Raum. Ein metrischer (Augabe-)Fehlervektor zum Zeitpunkt für eine endliche Testmenge mit ist ein Vektor
- definiert.

Definition - Fehlervektornorm für Maschinelles Lernen
Sei der Raum der endlichen Folgen in und eine Norm auf . Ferner sei ein Fehlervektor eines Maschinellen Lernprozesses gegeben.



definiert. Die Fehlervektornorm von ist dann mit .



Bemerkung - Fehlervektornorm für Maschinelles Lernen
Eine Norm ist auf einem Vektorraum definiert. Die Fehlervektornorm muss für unterschiedliche Trainingsdatenlängen definiert sein. Daher bettet man die Fehlervektoren in umgekehrter Reihenfolge in den Folgenraum ein.




Bemerkung - Neue Trainingsdaten für Maschinelles Lernen
Wird ein neues Ein-Ausgabepaar zum Testdatensatz ergänzt, so ergibt sich: Die Ergänzung von links ist hilfreich, um die Alterung von Daten bei einem Rechtsshift der Einträge innerhalb der Norm zu kodieren.



Alterung von Daten - erste Schritte
Für die Alterung von Daten betrachten man zunächst erste Schritte, die dann zu Verallgemeinerungen führen, die mit einem Skalarprodukt auf Folgenräumen ausgedrückt werden können. Zunächst einmal sollen aktuelle Daten mit einem Faktor 1 gewichtet werden und qualitativ bei älteren Daten die Gewichtung gegen 0 konvergieren. Dazu betrachten wir eine monoton fallende Alterungsfolge in (siehe Folgenräume).

Beispiel - Alterung von Daten
definiert eine Alterung auf den Daten.

Trainings- und Testdaten mit Zeitstempel
Als Trainingsdaten betrachtet man Ein-Ausgabepaare aus dem Kartesischen Produkt Ein-Ausgabegrundraum und der Zeitmenge . Der zusätzlich Zeitstempel für Trainingsdaten ist nun dann notwendig, wenn man das Alter der Trainingsdaten im Lernprozess berücksichtigen möchten. Ansonsten wählt man Trainings- und Testdaten für den maschinellen Lernprozess aus .



Bemerkung - Überwachtes Lernen
In dem obigen Annahmen geht man davon aus, dass ein überwachtes maschinelles Lernen verwendet wird und damit Sollwerte zu Eingabewerten . In einem unüberwachten Lernprozess bestehen die Trainingsdaten nur aus Daten . Die wird auch ein Kriterium sein, überwachtes und unüberwachtes Lernen bzgl. machinellen Lernalgorithmen zu unterscheiden.

Änderung der Wichtung über die Zeit
Wenn die Alterung von Trainingsdaten beim maschinellen Lernprozess berücksichtigt werden, kann man die Wichtung dynamisch bzgl. der aktuellen Zeit berechnen. Eine mögliche Option wäre bei einem aktuellen Zeitpunkt mit und :




Für setzt man . In dem obigen Term bestimmt , wie stark die Wichtung mit wachsendem Alter gegen 0 konvergiert.


Vorteil bzgl. Umordnung der Trainings- bzw. Testdaten
Mit einem berechneten Wichtungsvektors aus dem Alter der Trainingsdaten entfällt die Umordung. Insbesondere beim Online-Learning, bei dem kontinuierlich neue Trainingsdaten im Lernprozess z.B. eines künstlichen neuronalen Netzes berücksichtigt werden.

Aufgabe - Fehlervektornorm für Maschinelles Lernen
Definieren Sie eine Fehlernorm auf , die den Fehler bei älteren Daten weniger stark gewichtet! Welche Eigenschaften sollten die Wichtungen der Fehlernorm aufweisen?
Beispiel - lernfähiger Fuzzy-Controller
Betrachten Sie einen lernfähigen Fuzzy-Controller für eine Klimaanlage, der aus dem Regelungsverhalten der Personen im Raum erlernt, wann es den Personen zu warm oder zu kalt ist.
- mit und als Temperaturintervall.
- ist das Regelungsintervall am Heizkörper. 0 entspricht geschlossen und 1 entspricht der wärmsten Einstellung am Regler.
![{\displaystyle X:=[a,b]}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/40ee84e8cfb29b98ce24cbba1aeaa95f3fe14a32.svg)


![{\displaystyle Y:=[0,1]}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/d83aa65b6bf73c92e7c1f1e07f17578ac6fc3809.svg)
Diskrete Trainingsdaten
Wählen Sie in einer Tabellenkalkulation diskrete Trainingsdaten und rekonstruieren Sie daraus die Zugehörigskeitsfunktion für einen Fuzzy-Controller, der beschreibt, wann eine Temperatur für die Person in dem Raum angenehm ist.

Aufgabe - Optimierung bzgl. Nachhaltigkeit
Klimaanlagen benötigen viel Energie. Wie kann man das Regelungsverhalten optimieren, wenn man gleichzeitig weiß, wie viele Personen sich in einem Raum über den Tag bzw. im zeitlichen Verlauf befinden? Benennen Sie zunächst die Voraussetzung für den Definitionsbereich , wenn weitere inhaltliche Aspekte mit der Fuzzy-Zugehörigkeitsfunktion repräsentiert werden sollen! Welche fuzzy-logischen Operationen sind dafür notwendig.
Animation eines Lernprozesses
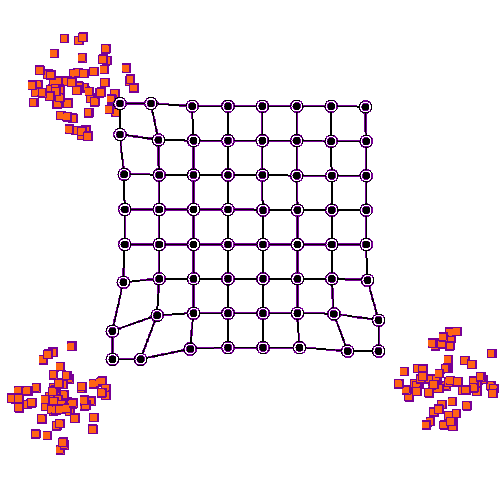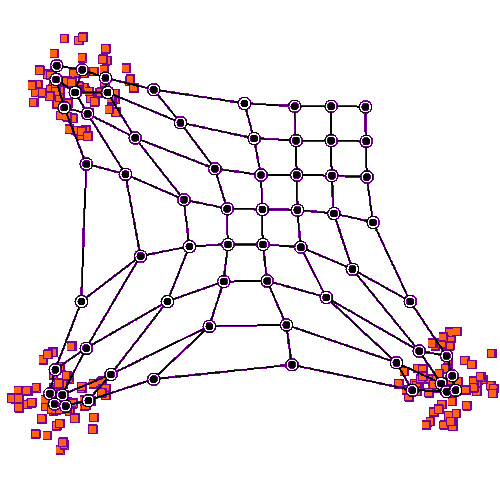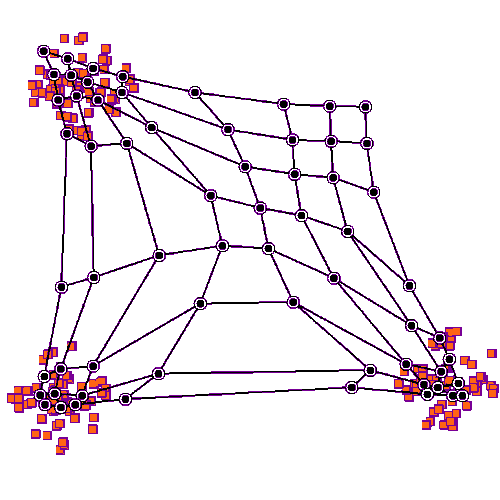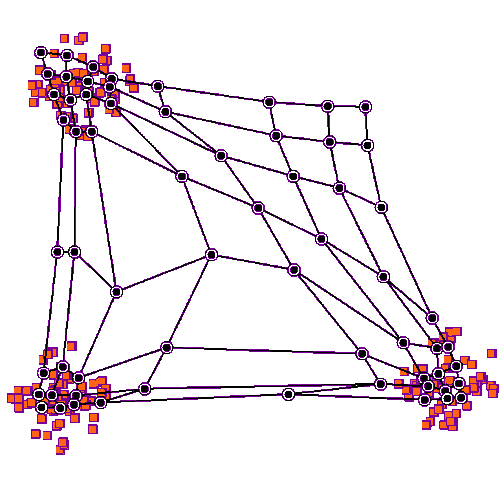
Mathematisches Grundkonzept für das Maschinelle Lernen
Dazu basieren Algorithmen beim maschinellen Lernen auf einem statistischen oder numerischen Modell, das mit Trainingsdaten "gefüttert" und ggf. mit Testdaten auf Güte getestet wird.
Mustererkennung - Erkennung von Gesetzmäßigkeiten
Beim maschinellen Lernen werden nicht einfach die Beispiele auswendig gelernt, sondern Muster und Gesetzmäßigkeiten sollen in den Lerndaten erkannt werden, damit durch die Lernphase diese Gesetzmäßigkeiten von dem System auch unbekannte Eingabedaten angewendet werden kann (siehe auch Lerntransfer).
Überanpassung - Overfitting
In der Regel wird durch das Maschinelle Lernen das lernfähige System auf den Trainingsdaten immer besser. Dieser Verbesserung wird z.B. durch numerische Verfahren, wie dem Gradientenabstiegsverfahren) generiert, mit dem man eine Fehlerfunktion schrittweise weiter minimiert. Dabei tritt das Phänomen der Überanpassung) auf.
Trainingsdaten
Auf den Trainingsdaten, die das lernfähige System für den maschinellen Lernprozess erhält, werden die Fehler in der Ausgabe geringer.
Testdaten
Auf den Testdaten, die das lernfähige System für den maschinellen Lernprozess keinen Zugriff. Die Testdaten dienen der Überprüfung der "Verallgemeinerungsfähigkeit" des lernfähigen Systems. Werden die Fehler in der Ausgabe nach einer gewissen Trainingszeit auf der Testmenge wieder signifikant schlechter, spricht man vom einer Überanpassung (engl. overfitting).[4][5]
Anwendungen
Aus dem weiten Spektrum möglicher Anwendungen seien hier genannt:
- Sprach- und Texterkennung,
- Intelligente Tutorielle Systeme (ITS) und Digitale Lernumgebungen
- automatisierte Diagnoseverfahren und autonome Systeme.
- Erkennung von Kreditkartenbetrug und Aktienmarktanalysen,
- Klassifikation von Nukleotidsequenzen.
Zusammenhang - Data Mining und Knowledge Discovery
Das Thema ist eng verwandt mit „Knowledge Discovery in Databases“ und „Data-Mining“, bei dem es jedoch vorwiegend um das Finden von neuen Mustern und Gesetzmäßigkeiten geht. Viele Algorithmen können für beide Zwecke verwendet werden.
Von Knowledge Discovery zu Maschinellem Lernen
Methoden der „Knowledge Discovery in Databases“ können genutzt werden, um Lerndaten für „maschinelles Lernen“ zu produzieren oder vorzuverarbeiten. Die Qualtität der Ausgaben von lernfähigen Systemen hängt maßgeblich von der Qualtiät der Trainingsdaten ab. Daher können Methoden der Erkennung von Wissens zur Qualitätsverbesserung der Ausgaben vom lernfähigen Systemen beitragen.
Maschinelles Lernen für Data Mining
Die Herausforderung in heutiger Zeit ist es, aus großen Wissen und Entscheidungsunterstützung abzuleiten. Wachsen die Datenmengen wird der Rechenaufwand größer und damit kommt man an Grenzen, in akzeptabler Zeit einen großen Suchraum zu analysieren. Hauptziel dabei ist es, einerseits den Berechnungsaufwand in einer Weise zu reduzieren, der andererseits keinen zu großen Einfluss auf die Güte der Ergebnisse hat. Also mit weniger Suchaufwand nahezu die gleiche Güte der Suchergebnisse zu behalten.
Symbolische und nicht-symbolische Ansätze
Beim maschinellen Lernen spielen Art und Mächtigkeit der Wissensrepräsentation eine wichtige Rolle. Man unterscheidet zwischen symbolischen Ansätzen und nicht-symbolischen Ansätzen.
Symbolische Ansätze
Bei symbolischen Ansätzen wird das Wissen – sowohl die Beispiele als auch die induzierten Regeln – explizit repräsentiert ist. Diese Regelsystemen können z.B. Fuzzy-Regelsysteme, bei denen die Gültigkeit einer Regel oder eines linguistischen Wertes durch einen maschinellen Lernprozess festgelegt werden.
Ein Spezialfall der Fuzzylogik sind symbolischen Ansätzen aus der AussagenlogikB und Prädikatenlogil. Vertreter der ersteren sind ID3 und sein Nachfolger C4.5. Letztere werden im Bereich der induktiven logischen Programmierung entwickelt.
Statistische Inferenz
Das Schließen von Daten auf (hypothetische) Modelle wird als Statistische Inferenz bezeichnet.
Nicht-symbolische Ansätze
Bei nicht-symbolischen Ansätzen, wie z.B. neuronalen Netzen, wird durch einen maschinellen Lernprozess ein berechenbares Verhalten „antrainiert“. Dabei geht es um eine möglichst gute Vorhersage von einem Systemverhalten durch das lernfähige System. Gütekriterium ist dabei die Vorhersagegüte. Dieses Vorgehen erlaubt jedoch keinen Einblick in die erlernten Lösungswege und ggf. vorhandene interne Regelsystem, das das Verhalten bestimmt. In einem solchen Fall wird das Wissen implizit repräsentiert.[6]
Deep Learning
Zu unterscheiden ist der Begriff zudem von dem Begriff „Deep Learning“, welches nur eine mögliche Lernvariante mittels künstlicher neuronaler Netze darstellt.
Hybride Ansätze
Bei hybdriden Ansätzen des maschinellen Lernens werden symbolische und nicht-symbolische Ansätze miteinander verbunden. Dies kann beispielsweise durch Neuro-Fuzzy-Systeme[7] erfolgen, bei denen die symbolische Ansätze durch Fuzzy-Regelsysteme abgedeckt werden und die nicht-symbolischen Ansätze durch neuronale Netze.
Algorithmische Ansätze
Die praktische Umsetzung geschieht mittels Algorithmen. Verschiedene Algorithmen aus dem Bereich des maschinellen Lernens lassen sich grob in drei Gruppen einteilen:[8] überwachtes Lernen (englisch supervised learning), unüberwachtes Lernen (englisch unsupervised learning) und bestärkendes Lernen (engl. reinforcement learning).
Automatisches Maschinelles Lernen
Automatisches maschinelles Lernen automatisiert viele Schritte des maschinellen Lernens.
Literatur
- Sebastian Raschka, Vahid Mirjalili (2017) Machine Learning mit Python und Scikit-Learn und TensorFlow: Das umfassende Praxis-Handbuch für Data Science, Predictive Analytics und Deep Learning URL: https://books.google.com/books?id=JM5CDwAAQBAJ - Date: 13. Dezember 2017, MITP-Verlags GmbH & Co. KG, 978-3-95845-735-5
- Andreas C. Müller, Sarah Guido: Einführung in Machine Learning mit Python. O’Reilly-Verlag, Heidelberg 2017, ISBN 978-3-96009-049-6.
- Christopher M. Bishop: Pattern Recognition and Machine Learning. Information Science and Statistics. Springer-Verlag, Berlin 2008, ISBN 978-0-387-31073-2.
- David J. C. MacKay: Information Theory, Inference and Learning Algorithms. Cambridge University Press, Cambridge 2003, ISBN 978-0-521-64298-9 (Online).
- Trevor Hastie, Robert Tibshirani, Jerome Friedman: The Elements of Statistical Learning. Data Mining, Inference, and Prediction. 2. Auflage. Springer-Verlag, 2008, ISBN 978-0-387-84857-0 (stanford.edu [PDF]).
- Thomas Mitchell: Machine Learning. Mcgraw-Hill, London 1997, ISBN 978-0-07-115467-3.
- D. Michie, D. J. Spiegelhalter: Machine Learning, Neural and Statistical Classification. In: Ellis Horwood Series in Artificial Intelligence. E. Horwood Verlag, New York 1994, ISBN 978-0-13-106360-0.
- Richard O. Duda, Peter E. Hart, David G. Stork: Pattern Classification. Wiley, New York 2001, ISBN 978-0-471-05669-0.
- David Barber: Bayesian Reasoning and Machine Learning. Cambridge University Press, Cambridge 2012, ISBN 978-0-521-51814-7.
- Arthur L. Samuel (1959): Some studies in machine learning using the game of checkers. IBM J Res Dev 3:210–229. doi:10.1147/rd.33.0210.
- Alexander L. Fradkov: Early History of Machine Learning. IFAC-PapersOnLine, Volume 53, Issue 2, 2020, Pages 1385-1390, doi:10.1016/j.ifacol.2020.12.1888.
Weblinks
- Machine Learning Crash Course. In: developers.google.com. Abgerufen am 6. November 2018 (englisch).
- Heinrich Vasce: Machine Learning - Grundlagen. In: Computerwoche. 13. Juli 2017, abgerufen am 16. Januar 2019.
- golem.de, Miroslav Stimac: So steigen Entwickler in Machine Learning ein, 12. November 2018
- Introduction to Machine Learning (englisch)
- Maschinen lernen – ohne Verstand ans Ziel, Wissenschaftsfeature, Deutschlandfunk, 10. April 2016. Audio, Manuskript
Siehe auch
- Künstliche Intelligenz
- Kurs:Maschinelles Lernen
- Föderales Lernen
- Empirische Risikominimierung
- Fuzzylogik
- Adaptives Neuro-Fuzzy-Inferenzsystem
- Statistische Inferenz
- Kurs:Maßtheorie auf topologischen Räumen
- Schwarmintelligenz
- Neuroinformatik
- Digitale Lernumgebung und Individualisierung und Differenzierung von Lehr-Lernmaterialien
Einzelnachweise
- ↑ Richard S. Sutton: Reinforcement learning : an introduction. Second edition - lSBN 978-0-262-03924-6 Auflage. Cambridge, Massachusetts 2018.
- ↑ Machine Learning: Definition, Algorithmen, Methoden und Beispiele. 11. August 2020, abgerufen am 31. Januar 2022.
- ↑ Marco Wiering, Martijn van Otterlo: Reinforcement learning : state-of-the-art. Springer, Berlin 2012, ISBN 978-3-642-27645-3.
- ↑ Tobias Reitmaier: Aktives Lernen für Klassifikationsprobleme unter der Nutzung von Strukturinformationen. kassel university press, Kassel 2015, ISBN 978-3-86219-999-0, S. 1 (Google books).
- ↑ Lillian Pierson: Data Science für Dummies. 1. Auflage. Wiley-VCH Verlag, Weinheim 2016, ISBN 978-3-527-80675-1, S. 105 f. (Google books).
- ↑ Pat Langley: The changing science of machine learning. In: Machine Learning. Band 82, Nr. 3, 18. Februar 2011, S. 275–279, doi:10.1007/s10994-011-5242-y.
- ↑ Kar, S., Das, S., & Ghosh, P. K. (2014). Applications of neuro fuzzy systems: A brief review and future outline. Applied Soft Computing, 15, 243-259.
- ↑ ftp://ftp.sas.com/pub/neural/FAQ.html#questions
Seiteninformation
Diese Lernresource können Sie als Wiki2Reveal-Foliensatz darstellen.
Wiki2Reveal
Dieser Wiki2Reveal Foliensatz wurde für den Lerneinheit Kurs:Maßtheorie auf topologischen Räumen' erstellt der Link für die Wiki2Reveal-Folien wurde mit dem Wiki2Reveal-Linkgenerator erstellt.
- Die Seite wurde als Dokumententyp PanDocElectron-SLIDE erstellt.
- Link zur Quelle in Wikiversity: https://de.wikiversity.org/wiki/Maschinelles%20Lernen
- siehe auch weitere Informationen zu Wiki2Reveal und unter Wiki2Reveal-Linkgenerator.
Wikipedia2Wikiversity
Diese Seite wurde auf Basis der folgenden Wikipedia-Quelle erstellt: