Der Begriff Memory Management Unit (MMU; deutsch Speicherverwaltungseinheit) benennt eine Hardwarekomponente eines Computers, die den Zugriff auf den Arbeitsspeicher verwaltet.
Aufgaben
Sie rechnet virtuelle Adressen jedes einzelnen Prozesses in physische Adressen des externen Speichers um.:59 Damit ermöglicht sie die Trennung zwischen Prozessspeicher und Hauptspeicher, was folgende Konzepte erlaubt:
- Auslagern von z. Z. nicht benötigtem Speicher
- Verzögertes Bereitstellen von angefordertem, aber noch nicht genutztem Speicher.
- Isolation von Prozessen untereinander und zwischen Prozess und Betriebssystem
- Sharing von einzelnen Seiten zwischen Prozessen (Shared Memory)
- Non-Sharing von Seiten zwischen Threads eines Prozesses (Thread-local storage)
- Einblenden von Dateien als Speicher (Memory-mapped files)
Die MMU regelt auch Speicherschutzaufgaben. So können einzelne Speicherbereiche für die Ausführung von Code oder zum weiteren Beschreiben gesperrt werden. Man unterscheidet hierbei zwischen der Abschottung von
- Programmen untereinander („horizontale Trennung“): Programme können (zum Beispiel bei Fehlern) nicht auf Speicher anderer Programme zugreifen.
- Programmen gegen das Betriebssystem („vertikale Hierarchie“): Das Funktionieren des Betriebssystems darf nicht durch (fehlerhafte) Anwendungsprogramme gefährdet werden. Dadurch ist der sichere Betrieb im Multitasking wesentlich einfacher, da die Hardware verhindert, dass ein Fehler in einem Prozess zu einem direkten Zugriff auf Daten eines anderen Prozesses oder des Betriebssystems führt. Außerdem kann durch die MMU jedem Prozess ein initial unfragmentierter, exklusiver Speicherraum präsentiert werden.
Einsatz und Verwendung
Block Diagramm Skylake CPU
Link zum Bild
(Bitte Urheberrechte beachten)
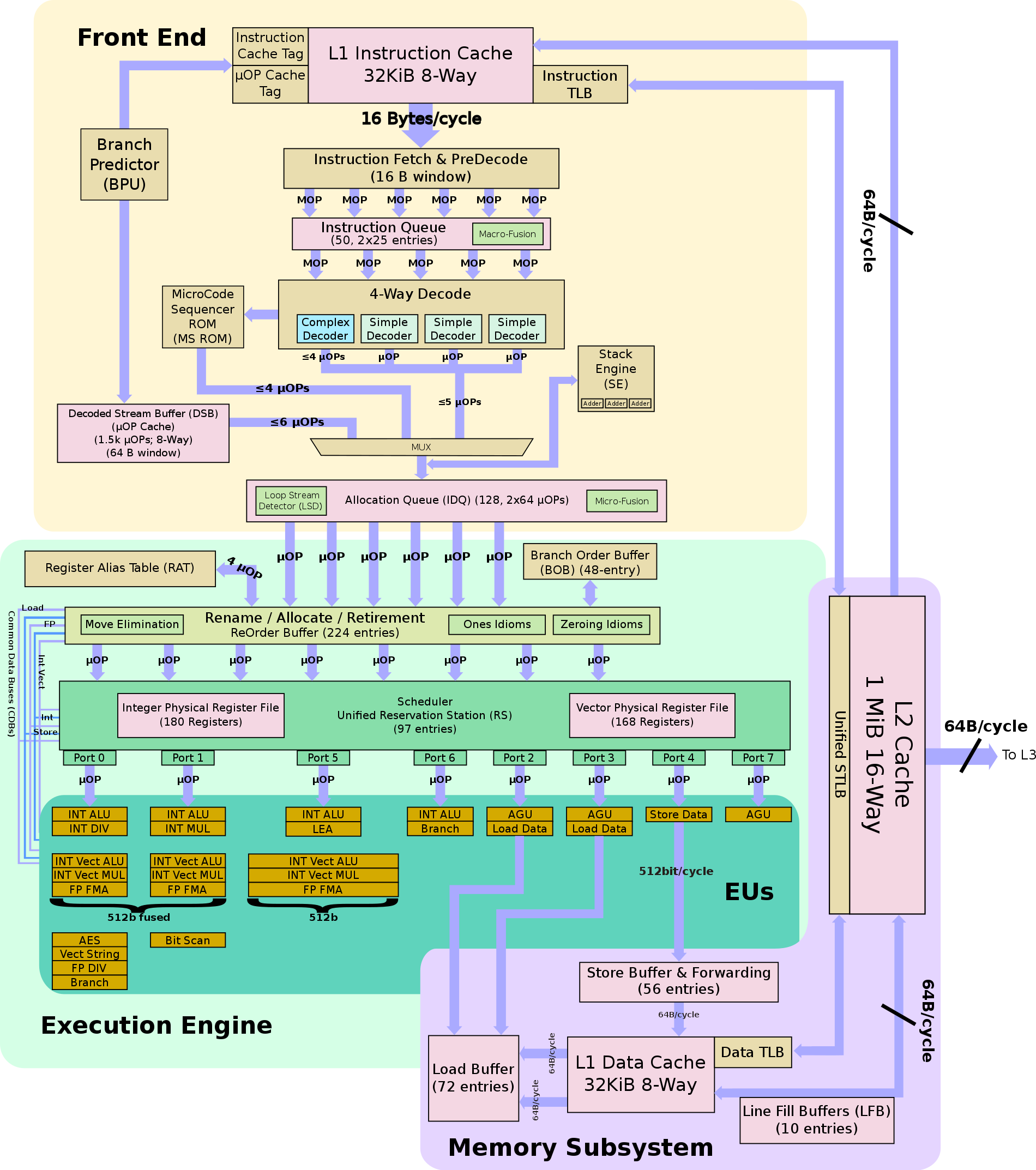{kind=link}
MMUs waren ursprünglich als externe und optionale Zusatzkomponente für Mikroprozessoren konzipiert. Typische Beispiele sind die 16-Bit-CPU Motorola MC68010, die MMU war in einem externen Baustein MC68451 untergebracht. Andere Hersteller wie Zilog und Intel integrierten die MMU direkt in den Prozessor (Z8001, Intel 80286). Mit dem Aufkommen von Caches in CPUs ist die MMU in die CPU verlagert worden.
Dies ist zwingend notwendig, da sich die MMU zwischen CPU-Kern und dem/den Caches befinden muss. Sie arbeitet mit physischen Adressen, um nicht bei jedem Thread- oder Taskwechsel geflusht werden zu müssen. Multicore-Systeme mit geteiltem Cache erfordern zwingend die MMU vor diesem geteilten Cache.
| MMU-Instruction | L1I-Cache | ||||||||||||||||||||||||||||||||||||||||||||
| CPU-Kern | L2-Cache | L3-Cache | Hauptspeicher | ||||||||||||||||||||||||||||||||||||||||||
| MMU-Data | L1D-Cache | ||||||||||||||||||||||||||||||||||||||||||||
| MMU-Instruction | L1I-Cache | ||||||||||||||||||||||||||||||||||||||||||||
| CPU-Kern 1 | L2-Cache | ||||||||||||||||||||||||||||||||||||||||||||
| MMU-Data | L1D-Cache | ||||||||||||||||||||||||||||||||||||||||||||
| shared L3-Cache | Hauptspeicher | ||||||||||||||||||||||||||||||||||||||||||||
| MMU-Instruction | L1I-Cache | ||||||||||||||||||||||||||||||||||||||||||||
| CPU-Kern 2 | L2-Cache | ||||||||||||||||||||||||||||||||||||||||||||
| MMU-Data | L1D-Cache | ||||||||||||||||||||||||||||||||||||||||||||
Bei Rechnern mit Harvard-Architektur gibt es zwei MMUs pro Kern – eine für den Befehls- und eine für den Datenspeicher jedes Kerns. Waren früher MMUs "Luxusartikel", so sind sie heutzutage teilweise selbst in CPUs im Preisbereich um 1 US$ Standard (BCM2835).
Funktionsprinzip
Jeder durch einen Befehl angeforderte Lese- oder Schreibzugriff wird zuerst auf seine Gültigkeit geprüft und bei Validität durch die Memory Management Unit in eine physische Adresse umgerechnet. Selbstnachladende MMUs haben einen speziellen Cache-Speicher, den Translation Lookaside Buffer, der jeweils die letzten Adressübersetzungen cacht und so häufige Zugriffe auf die Übersetzungstabelle reduziert. Darüber hinaus enthält die MMU spezielle schnelle Register (wie etwa für Basisadressen und Offsets), um die Adressberechnung so effizient wie möglich auszuführen. Man unterscheidet die möglichen Arten der Adressübersetzung (englisch address translation) nach der Art der verwendeten Seitentabellen.
Ursprünglich gab es zwei Methoden der Adressumsetzung, diejenige nach Segmenten (segmented MMU) und diejenige nach Seiten (paged MMU). Bei der Adressumsetzung nach Segmenten werden jeweils logische Speicherbereiche variabler Größe auf einen physischen Speicherbereich gleicher Größe umgesetzt. Da dieses Verfahren jedoch nicht gut mit der Speicherverwaltung moderner Betriebssysteme mit virtueller Speicherverwaltung zusammenpasst, ist es kaum noch in Verwendung. Die Adressumsetzung nach Seiten verwendet normalerweise feste Blockgrößen und ist heute die übliche Methode. Den Mechanismus der Übersetzung von logischen Adressen in physische Adressen bezeichnet man daher im Fall der festen Blockgrößen auch als Paging. Bei Prozessen mit sehr großem Adressraum würde bei fester Blockgröße eine sehr große Anzahl von Tabelleneinträgen in der MMU nötig. Daher können einige Betriebssysteme, bei Vorhandensein einer entsprechenden MMU, Teile des Adressraums durch Seiteneinträge zusammenfassen, die wesentlich größere Blockgrößen verwenden. Einer logischen Adresse muss nicht jederzeit eine physische zugeordnet sein. Wird eine solche Adresse angesprochen, erfolgt ein sogenannter Seitenfehler (englisch page fault, page miss), woraufhin das Betriebssystem die Daten von einem externen Speichermedium laden kann; dieser Vorgang läuft für eine Applikation transparent ab. Man spricht hier von „Speichervirtualisierung“.
Siehe auch
Literatur
- Andrew S. Tanenbaum: Moderne Betriebssysteme. 4., überarbeitete Auflage. Hallbergmoos: Pearson-Studium, 2016, ISBN 978-3-86894-270-5.
- Eduard Glatz: Betriebssysteme – Grundlagen, Konzepte, Systemprogrammierung. 2., aktualisierte und überarbeitete Auflage. dpunkt Verlag, 2010, ISBN 978-3-89864-678-9.
- Erich Ehses, et al.: Betriebssysteme. Ein Lehrbuch mit Übungen zur Systemprogrammierung in UNIX/Linux. München: Pearson-Studium 2005. ISBN 3-8273-7156-2. S. 273 ff.